이번 강좌에서는 파일을 읽고 쓰는 방법에 대해서 공부해보도록 하겠습니다.
개발을 하다보면 파일에서 데이터를 읽어들여 처리하거나, 어떤 결과물을 파일로 남기기도 하고, 프로그램에 문제가 생기면 에러 로그를 파일로 남기는 경우가 아주 많습니다.
파이썬에서 주로 다루는 파일 형식
- TEXT
- CSV
- JSON
- YAML
- EXCEL
- Image
파이썬으로 주로 다루는 파일은 일반 텍스트 파일, CSV, JSON, YAML, EXCEL, PDF, image 파일 등이 있습니다. 이번 강좌는 기초강좌이니 일반 텍스트 파일을 읽고 쓰는 방법에 대해서만 공부하도록 하겠습니다.
먼저 파일을 읽는 방법에 대해서 알아보겠습니다.
파일을 읽기 위해서는 먼저 파일을 열어야하는데요, 파일을 열기 위해서는 내장 함수인 open 함수를 사용해야합니다. open 함수는 여러개의 파라미터를 가지고 있는데요, 지금은 file, mode, encoding 이 3개의 파라미터만 기억하시기 바랍니다.
open(file='data.txt', mode='r', encoding='utf8')File 파라미터에는 파일경로가 들어가는데요, 파일의 절대경로나 파이썬 파일로 부터의 상대경로를 입력하시면 되고, 만약에 파일이 파이썬 실행 파일과 같은 폴더에 있다면 파일 이름만 입력하셔도 됩니다.
다음은 모드 파라미터에 들어갈 수 있는 옵션에 대해서 알아보겠습니다.
파일 읽기, 쓰기 모드
| 모드 | 설명 |
|---|---|
| r | 읽기 전용 모드이며 디폴트 옵션이기 때문에 생략을 하셔도 됩니다. |
| w | 쓰기 전용 모드이며, 같은 이름의 파일이 없으면 새로운 파일을 생성하고, 있으면 덮어쓰기를 합니다. 덮어쓰기를 하면 기존 파일의 데이터가 모드 지워지니 주의하시기 바랍니다. |
| x | 쓰기 전용 모드이지만, 같은 이름의 파일이 존재하면 에러를 발생시킵니다. w 모드의 안전모드라고 생각하시면 됩니다. |
| a | 추가 모드이며, 같은 이름의 파일이 없으면 새로운 파일을 생성하고, 있으면 하단에서 부터 이어쓰기를 하는 모드입니다. |
| t | 텍스트 모드로 디폴트 모드이니 생략이 가능합니다. |
| b | 바이너리 모드로 PDF나 이미지 파일등과 같이 일반 텍스트 파일이 아닌 바이너리로 만들어진 파일을 열 때 사용하는 모드입니다. |
| r+ | 읽기와 쓰기를 동시에 할 수 있는 모드입니다. |
| w+ | 읽기와 쓰기를 동시에 할 수 있는 모드입니다. |
이번 강좌에서는 r, w, x, a 이 4개의 모드에 대해서만 살펴보겠습니다.
인코딩 파라미터는 "cp932"가 디폴트 값으로 정의되어 있고, 한글이나 중국어, 일본어와 같은 유니코드 문자가 들어간 파일을 읽고 쓰려면 "utf8" 옵션을 사용하셔야 합니다.
아래와 같이 여러 국가명, 수도명, 지역명이 들어간 데이터를 country.txt 라는 이름의 텍스트 파일에 저장한 후, 파이썬을 통해서 읽어 보도록 하겠습니다.
대한민국,서울,아시아
일본,동경,아시아
중국,베이징,아시아
영국,런던,유럽
프랑스,파리,유럽
이탈리아,로마,유럽먼저 open 함수를 사용하여 리턴된 값을 확인해보도록 하겠습니다. 파일 파라미터에는 파일 경로를 전달해야 하는데, 아래 파일은 파이썬 실행 파일과 같은 폴더에 있기 때문에 파일 이름만 입력하겠습니다. 읽기모드인 r 모드를 사용하고, 한글은 유니코드 문자이기 때문에 인코딩에는 utf8 옵션을 사용하겠습니다.
file = open(file='country.txt', mode='r', encoding='utf8')
print(file)<_io.TextIOWrapper name='country.txt' mode='r' encoding='utf8'>Open 함수가 TextIOWrapper라는 오브젝트가 리턴한 것을 알 수 있습니다. 이 오브젝트는 메소드를 아주 많이 가지고 있는데요, 그중에서 read 메소드를 사용해보겠습니다.
file = open(file='country.txt', mode='r', encoding='utf8')
print(file.read())
file.close()대한민국,서울,아시아
일본,동경,아시아
중국,베이징,아시아
영국,런던,유럽
프랑스,파리,유럽
이탈리아,로마,유럽Country.txt 파일의 내용이 그대로 출력 되었습니다.
open 함수를 사용해서 파일을 열어서 사용한 다음에는 close 메소드를 사용해서 꼭 파일을 닫아주셔야합니다. 프로그램이 종료되면서 파일이 자동으로 닫히기는 하는데요, 프로그램이 실행되고 있는 동안은 파일에 락이 걸려서 다른 사람이나 다른 프로그램이 파일에 엑세스를 할 수가 없게 됩니다. 이 점 꼭 주의하셔야 하는데요, 그래서 이런식으로 파일에 엑세스하는 것 보다는 컨텍스트 매니저를 사용하시는게 더 좋습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
print(file.read()) # 실행블록
# file.close() # with 키워드를 사용하면 close 메소드를 사용하지 않아도 됩니다.컨텍스트 매니저는 with 키워드로 시작하고 오브젝트를 저장하는 변수를 as 키워드 뒤에 놓으시면 됩니다.
여기 들여쓰기가 된 부분 부터가 실행블록인데요, 이 실행블록이 종료되면 컨텍스트 메니저는 파일을 자동으로 클로즈합니다.
파일 오브젝트는 closed 라는 속성을 가지고 있는데요, 이것을 사용하면 파일이 잘 닫혔는지 확인 할 수 있습니다.
진짜로 파일이 잘 닫혔는지 확인해 보겠습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
print('[with 문 안에서 실행]' , file.closed)
print(file.read())
print('[with 문 밖에서 실행]' , file.closed)[with 문 안에서 실행] False
대한민국,서울,아시아
일본,동경,아시아
중국,베이징,아시아
영국,런던,유럽
프랑스,파리,유럽
이탈리아,로마,유럽
[with 문 밖에서 실행] Truewith 문 안에서는 파일이 열려있는 상태이고, with 문 밖에서는 파일이 닫혀있는 상태임을 확인하였습니다.
Read 메소드는 n 이라는 파라미터에 정수를 입력 받는데요, 이 파라미터를 사용하면 숫자만큼의 글자만 읽어서 리턴하게 됩니다.
4를 입력해서 대한민국 4자글자만 출력해 보겠습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
print(file.read(4))대한민국파일 오브젝트는 내부적으로 커서라는 것이 작동해서 파일을 오픈하면 파일 제일 첫 부분에 커서를 위치시킵니다. 그리고 read 메소드를 실행하면 그 숫자만큼 커서를 이동하면서 글자를 읽습니다. 조금 전처럼 4글자를 읽어들이면 커서는 4번 이동하게 되죠. 그리고 또 read 함수를 실행하면, 커서가 이동한 위치부터 읽어 들이게 됩니다.
이번에는 컴마와 단어를 따로 따로 출력해 보겠습니다. 아래 코드를 실행하면 커서가 read 함수에 전달된 숫자만큼 이동하면서 텍스트를 읽게 됩니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
print(file.read(4))
print(file.read(1))
print(file.read(2))
print(file.read(1))
print(file.read(3))대한민국
,
서울
,
아시아그럼 아래와 같이 read 메소드를 2번 실행하면 전체 파일이 2번 출력될까요? 실행해 보겠습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
print(file.read())
print(file.read())대한민국,서울,아시아
일본,동경,아시아
중국,베이징,아시아
영국,런던,유럽
프랑스,파리,유럽
이탈리아,로마,유럽한 번만 출력되는 것을 볼 수 있습니다. 이유는 처음 read 메소드를 실행하면 커서가 파일 마지막에 위치하게 되고, 두 번째 read 메소드가 실행됐을 때는 더 이상 읽어들일 글자가 없기 때문에 아무것도 리턴하지 않고 종료되기 때문입니다. 만약에 전체 파일을 두 번 읽고 싶으시면 seek 메소드를 사용하시면 됩니다. seek 메소드에 숫자 0을 전달하고 실행하면 커서가 파일의 맨 앞으로 이동하게 됩니다.
그럼 seek 메소드를 사용해 보겠습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
print(file.read())
file.seek(0)
print(file.read())대한민국,서울,아시아
일본,동경,아시아
중국,베이징,아시아
영국,런던,유럽
프랑스,파리,유럽
이탈리아,로마,유럽
대한민국,서울,아시아
일본,동경,아시아
중국,베이징,아시아
영국,런던,유럽
프랑스,파리,유럽
이탈리아,로마,유럽파일이 두 번 출력되는 것을 볼 수 있습니다.
이번에는 파일 오브젝트가 가지고 있는 reallines라는 메소드를 사용해 보겠습니다. 이 메소드는 모든 줄을 리스트의 아이템으로 저장해서 전체 파일의 텍스트를 하나의 리스트로 리턴합니다.
실행해보겠습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
lines = file.readlines()
print(lines)['대한민국,서울,아시아\n', '일본,동경,아시아\n', '중국,베이징,아시아\n', '영국,런던,유럽\n', '프랑스,파리,유럽\n', '이탈리아,로마,유럽']한 줄 한 줄씩 리스트에 잘 저장되어 리턴된 것을 볼 수 있습니다. 이렇게 리스트를 만드는 이유는 루핑을 돌면서 데이터를 처리하기 위해서인데요, for 반복문을 사용해서 출력해 보겠습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
lines = file.readlines()
for line in lines:
print(line)대한민국,서울,아시아
일본,동경,아시아
중국,베이징,아시아
영국,런던,유럽
프랑스,파리,유럽
이탈리아,로마,유럽실제 파일의 데이터와는 다르게 각 줄 사이에 빈 줄이 추가되었습니다. 이 이유는 각 리스트 아이템의 마지막에 뉴라인 케릭터가 있고 프린트 함수도 줄바꿈을 하기 때문에 각 줄마다 줄바꿈이 두 번 발생한 것입니다.
이 문제는 아래 코드와 같이 print 함수의 end 파라미터에 빈 문자열을 전달하여 줄바꿈을 하지 않도록하여 해결할 수 있습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
lines = file.readlines()
for line in lines:
print(line, end='')대한민국,서울,아시아
일본,동경,아시아
중국,베이징,아시아
영국,런던,유럽
프랑스,파리,유럽
이탈리아,로마,유럽이번에는 지역별로 나라를 필터링 하는 기능을 만들어 보겠습니다. 먼저 각 줄을 컴마를 기준으로 스플릿하여 리스트에 저장하겠습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
lines = file.readlines()
countries = []
for line in lines:
countries.append(line.split(','))
print(countries)[['대한민국', '서울', '아시아\n'], ['일본', '동경', '아시아\n'], ['중국', '베이징', '아시아\n'], ['영국', '런던', '유럽\n'], ['프랑스', '파리', '유럽\n'], ['이탈리아', '로마', '유럽']]지역명에 뉴라인 케릭터가 남아있네요. 스트립 메소드를 사용하여 지우겠습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
lines = file.readlines()
countries = []
for line in lines:
split_items = [x.strip() for x in line.split(',')]
countries.append(split_items)
print(countries)[['대한민국', '서울', '아시아'], ['일본', '동경', '아시아'], ['중국', '베이징', '아시아'], ['영국', '런던', '유럽'], ['프랑스', '파리', '유럽'], ['이탈리아', '로마', '유럽']]깨끗히 지워졌습니다. 그럼 이번에는 if 문을 사용하여 아시아 국가만 출력해 보겠습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
lines = file.readlines()
countries = []
for line in lines:
split_items = [x.strip() for x in line.split(',')]
countries.append(split_items)
print('아시아 국가:')
for country in countries:
if country[2] == '아시아':
print('- {}'.format(country[0]))아시아 국가:
- 대한민국
- 일본
- 중국countries 변수에 저장된 데이터를 재사용하여 유럽 국가를 추가로 필터링해 보겠습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
lines = file.readlines()
countries = []
for line in lines:
split_items = [x.strip() for x in line.split(',')]
countries.append(split_items)
print('아시아 국가:')
for country in countries:
if country[2] == '아시아':
print('- {}'.format(country[0]))
print('\n유럽 국가:')
for country in countries:
if country[2] == '유럽':
print('- {}'.format(country[0]))아시아 국가:
- 대한민국
- 일본
- 중국
유럽 국가:
- 영국
- 프랑스
- 이탈리아그런데 위와 같이 read 메소드나 readlines 메소드로 사이즈가 큰 파일을 열면 파일안의 모든 텍스트를 메모리상에 저장하기 때문에 메모리 리소스를 낭비하는 문제가 발생합니다. 메모리만 많이 사용하는게 아니라 프로그램의 퍼포먼스도 떨어지게 됩니다. 파일 하나 읽는데 몇기가나 메모리를 사용하면서도 느린 프로그램은 아무도 사용하려고 하지 않을겁니다. read 나 readlines 메소드는 작은 파일을 읽을 때는 사용해도 문제 없지만 큰 사이즈의 파일을 읽을 때는 다른 방법을 사용하여야 합니다.
파일 오브젝트는 for 반복문에서 바로 사용할 수가 있으며 한 번 루프를 돌때마다 텍스트 한 줄씩을 리턴합니다. 이 기능을 사용하면 파일의 모든 데이터를 메모리에 로딩하지 않고도 모든 데이터를 읽을 수가 있습니다. 실행해 보겠습니다.
with open(file='country.txt', mode='r', encoding='utf8') as file:
for line in file:
print(line, end='')대한민국,서울,아시아
일본,동경,아시아
중국,베이징,아시아
영국,런던,유럽
프랑스,파리,유럽
이탈리아,로마,유럽실제로 read 메소드를 사용했을 때와 사용 안 했을 때의 메모리 사용량과 퍼포먼스를 비교해 보겠습니다. 비교 테스트를 위해서 사전에 135MB 정도 되는 파일을 준비했습니다. 먼저 time 패키지를 사용해서 프로그램의 실행 시간을 측정하는 코드를 만들어 보겠습니다. 프로그램이 종료되는 시간에서 시작한 시간을 빼면 프로그램의 실행 시간이 초로 출력되게 됩니다.
먼저 read 메소드를 테스트해 보겠습니다.
import time
start = time.time()
with open(file='big_file.txt', mode='r', encoding='utf8') as file:
text = file.read()
for line in text.splitlines():
print(line)
end = time.time()
time_took = end - start
print('실행 시간: {} 초'.format(time_took))line 1
line 2
...
line 9999998
line 9999999
실행 시간: 407.7338275909424 초read 함수의 테스트는 407 초가 소요됐습니다. 하기 이미지와 같이 실행 중 824.4 MB의 대량의 메모리를 점유하는 것을 확인하였습니다.
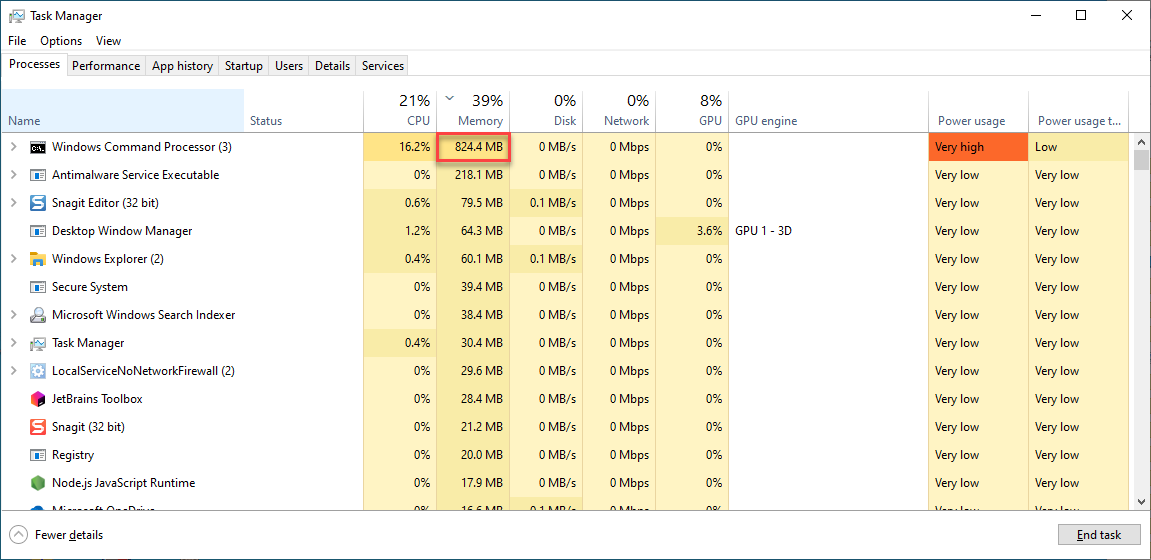
이번에는 file 오브젝트를 for 반복문에서 바로 사용해 보겠습니다.
import time
start = time.time()
with open(file='big_file.txt', mode='r', encoding='utf8') as file:
# text = file.read()
for line in file:
print(line, end='')
end = time.time()
time_took = end - start
print('실행 시간: {} 초'.format(time_took))line 1
line 2
...
line 9999998
line 9999999
실행 시간: 405.07602643966675 초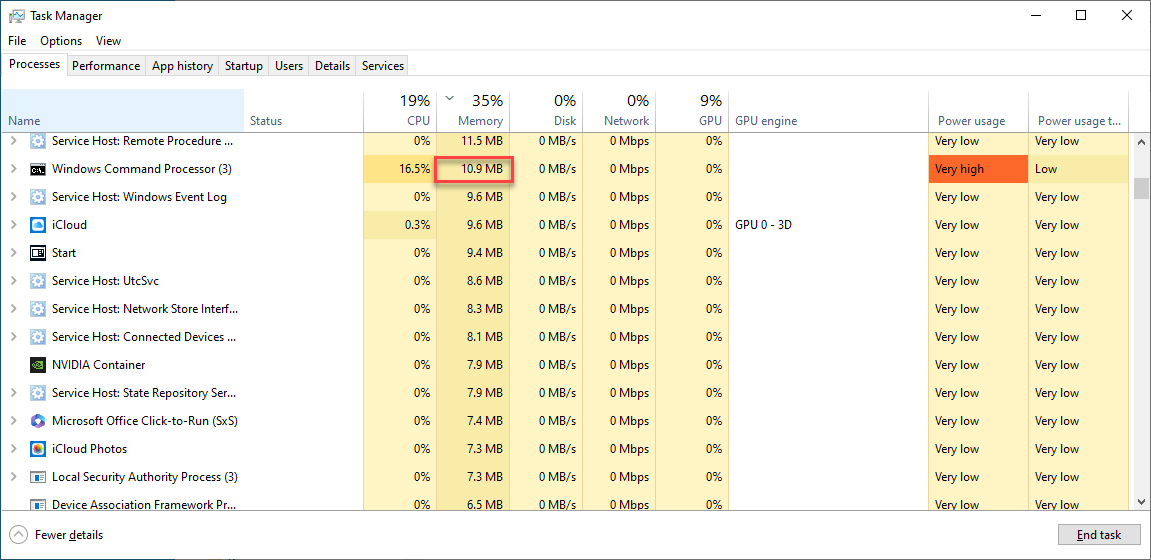
어떤가요 read 메소드를 사용하는 것보다 file 오브젝트를 직접 for 반복문에서 사용하는 쪽이 메모리를 훨씬 적게 사용하면서도 실행시간도 짧은 것을 볼 수 있었습니다.
다음 강좌에서는 파일 쓰기에 대해서 공부하도록 하겠습니다. 감사합니다.